
Batch jobs are a stalwart of any enterprise software collection. Even in this world of event driven architectures we cannot escape the fact that database jobs, and file based csv input/output probably drives the majority of our banking systems and various integrations.
For batch applications, I personally really like the spring-batch framework, of course, there are many alternatives. It is also possible to use Camel for batch processing, but I far prefer using spring-batch for batching, and camel for any integration parts via the camel-spring-batch component. Spring-batch is not the fastest batch framework, but has many options to partition and improve speeds, all while maintaining a great set of reporting metadata for the status of any jobs run.
Where can containers fit into all this? Well, in a containerized world we are not limited to Java technology, we can now use Kubernetes/Openshift to orchestrate containers for us as part of an overall batch flow. In this article I will demonstate a simple flow where a csv file is generated by one container as the input to a spring-batch flow. This is achieved by using the io.fabric8/openshift-client to interact with the cluster and create an Openshift/Kubernetes Job as part of the flow.
Why would you want to do this? There are some things you can do in different languages, or even plain bash which are far quicker than doing in Java. Sure, you may lose some of the funky metadata, but such orchestration could dramatically speed up your batch jobs.
Jobs within Jobs
In this post I’ll aim to show you how we can get spring-batch jobs up and running inside Openshift, and the spring batch job itself running as an Openshift/Kubernetes Job.
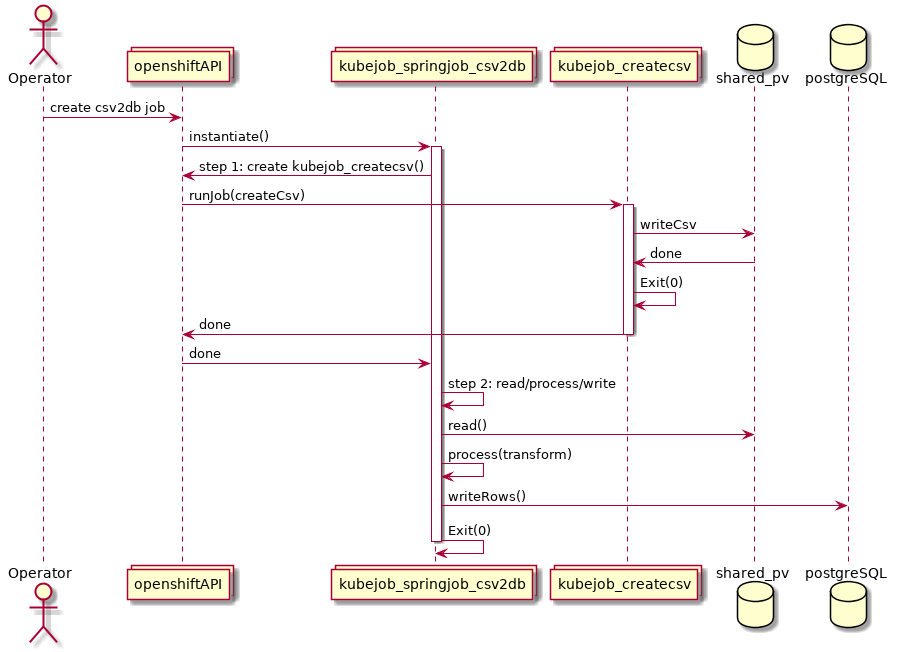
- An Openshift Job is created which runs a spring-batch job with the steps below with two parameters (jobFileLocation and batchRun)
- Step 1 creates a new bash container as an Openshift job that generates a CSV file and places it in a location (on a shared persistentVolume)
- Step 2 continues the spring-batch job which will read the file, process the file, and pushes the data into the database.
- During Step 1 the spring-batch application uses the OpenshiftJobTasklet which uses the fabric8 OpenShiftClient. This is what instructs the cluster to spin up a new Job.
Please note that jobFileLocation is passed in as a jobParameter and this is actually the location where the csv file will be generated and read from.
The job containers mount the shared persistent volume on /test.
Also note the command field:
command: ["java", "-jar", "/deployments/csv2db-batch-ocp-1.0.jar", "importUserJob", "jobFileLocation=/test/myfile2.csv", "batchRun=2"]
- importUserJob = the name of the spring batch job
- jobFileLocation=/test/myfile2.csv - name of the file to create/process
- batchRun=2 is another jobParameter
The steps below will clone the code from https://github.com/welshstew/csv2db-batch-ocp which has a spring-batch job pre-configured.
Setting up the environment to run a spring-batch job
The following commands should produce a new image and imagestream in openshift/minishift:
The resulting image should be added to a new imagestream:
We are now in a position to be able to run this container as a job in the environment.
Running the spring-batch job as an Openshift/Kubernetes job
Let’s create the job in Openshift, note that in the definition of the job that we mount the configmap and tell spring where the config is using the SPRING_CONFIG_LOCATION environment variable. The persistent volume is mounted to /test as mentioned previously.
Checking the logs of the job oc logs job/csv2db-job-1 reveals that something isn’t quite right with the job:
We need to fix this by applying the correct permissions to allow this user to watch pods, and also be able to create jobs in this namespace.
We will delete this job, fix the permissions, and instantiate a new job below:
We should now see that the appropriate pods are started, then run to completion.
You will notice that our csv2db-job-2 actually generated another Openshift/Kubernetes job as part of the job run.
The code responsible for this is in the OpenshiftJobTasklet.java
The code uses a JobBuilder in order to create a new job definition and creates it using the DefaultOpenShiftClient.
Marvelous Metadata
Spring Batch has fantastic meta data for keeping track of Jobs and Job Steps, successful steps and failed steps.
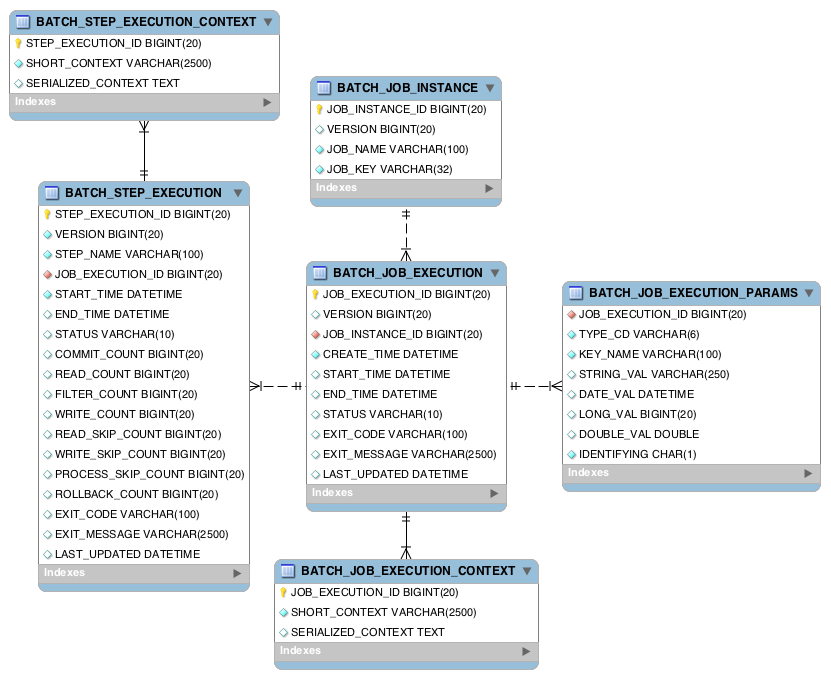
We can interrogate the postgres database to see what has been collected in this metadata:
We can see that we have had two job instances created. Now let’s have a look at the step executions:
Our first job failed, we know why, but we can always have a look at the exit message to give us an idea why…
Sure, the message may be untidy via the rsh/shell, but at least we have some good meta data when we are running spring batch jobs to figure out why things didn’t work.
We can also confirm that our people table has people in it…
Let’s generate another 10 people via another job/terminal:
Of course, the spring-batch meta data is again updated as appropriate.
A word on Quality of Service Tiers
More information on these tiers and limits can be found in the
Openshift Complete Resources Guide.
In this example of batch jobs I have set everything to be Guaranteed, and have set the requests and limits to be the same for the jobs to ensure the pods are guaranteed
cpu and memory resources.
Openshift has three tiers of QoS:
- Best Effort
- Burstable
- Guaranteed
To break it down:
- No Requests or Limits == “Best Effort”
- Requests set, and Limits set with higher values == “Burstable”
- Requests and Limits are set to the same values == “Guaranteed”
Spring Batch Admin Deprecated :(
Spring Batch Admin is a user interface for Spring Batch Jobs. I’ve used this during previous jobs, but this was using older versions of Spring (3.x.x).
Unfortunately Spring Batch Admin is a real PITA to get working with Spring Boot. It’s pretty obvious that the project has been deprecated in favour of Spring Cloud Data Flow. This is all fully tied in with the Spring ecosystem and other Spring based products. The purpose of this article was just to show how you can use spring-batch along with the io.fabric8/openshift-client to orchestrate containers and jobs.
References
